Wyliczanie ARPU w KNIME
Niniejszy artykuł stanowi kontynuację tematyki zapoznania czytelników z funkcjonalnościami oprogramowania KNIME. Tym razem przedstawione zostanie praktyczne wykorzystanie tej platformy analitycznej na prostym przykładzie wyliczania ARPU – KPI popularnego w zarządzaniu finansami.






KNIME – nie taki Data Mining straszny
W artykułach Karola Maruszy zawartych w poprzednich numerach czytelnicy mieli możliwość zapoznania się z platformą analityczną KNIME (Knime Analytics Platform).
Jest to coraz częściej wybierane przez analityków danych oprogramowanie do zaawansowanego przetwarzania danych, ich analizy i automatyzacji procesów. Lista funkcjonalności KNIME jest ogromna i cały czas rozwijana. KNIME jest intuicyjny w obsłudze, ma przyjazny interfejs, potrafi wykonać złożone operacje na danych, zapewnia integrację z innymi narzędziami analizy i przetwarzania danych, takimi jak R czy JAVA. Nie bez znaczenia jest również fakt, że KNIME w wersji desktopowej jest narzędziem darmowym. W efekcie wokół KNIME utworzyła się spora społeczność, która zbudowała forum z rozwiązaniami wielu bardziej złożonych zastosowań.
https://www.knime.com/knime-community
Zalety KNIME docenił również Gartner w swoim Magic Quadrant. Poniższy wykres pokazuje wiodące na początku 2017 r. narzędzia Data Mining. KNIME i RapidMiner (również darmowe i popularne narzędzie) są w grupie liderów i wizjonerów oprogramowania bezpośrednio obok takich potęg jak SAS i IMB (chodzi tu głównie o zakupione w 2009 r. przez IBM oprogramowanie SPSS Modeler i SPSS Statistics).
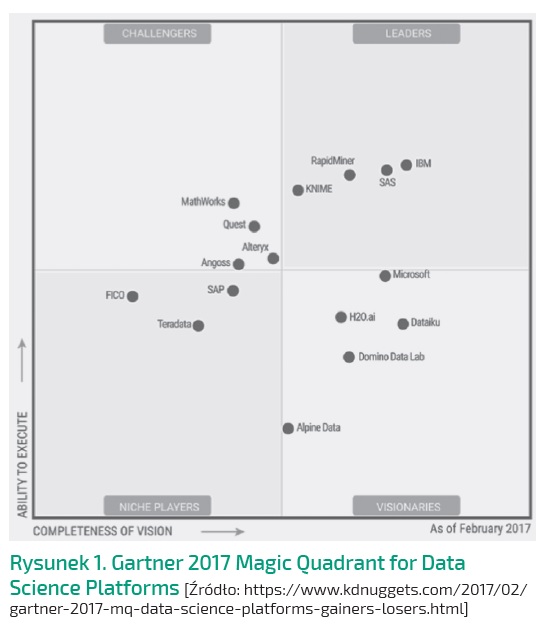
KNIME z powodzeniem może zastąpić czy też wzbogacić w pracy Excela i jestem przekonany, że oferuje więcej. Tyle na temat propagowania KNIME, teraz przejdźmy do jego zastosowania w praktyce.
ARPU
W niniejszym artykule przedstawię bardzo proste zastosowanie KNIME na przykładzie wyliczenia ARPU na fikcyjnych danych. Na początek zdefiniujmy sobie ten termin. Definicję przytoczę za finansopedia.forsal.pl.
ARPU (ang. Average revenue per user lub average revenue per unit) – wskaźnik opisujący średni miesięczny przychód firmy w przeliczeniu na jednego abonenta. Jest to wskaźnik najczęściej używany do porównywania skuteczności firm w branży telekomunikacyjnej. Jest on jednak także stosowany w branżach pokrewnych, np. w sieciach telewizji kablowej. Źródło: http://finansopedia.forsal.pl/encyklopedia/finanse/hasla/911564,arpu.html
Zatem wszędzie tam, gdzie przychody z klientów oparte są na jakiejś formie abonamentu, ARPU znajdzie swoje zastosowanie. W swojej praktyce wyliczałem ARPU nie tylko miesięczne. W zależności od celów analizy i struktury danych możemy zmodyfikować powyższą definicję do skali roku lub w drugą stronę, np. dnia.
ARPU pojawiło się w mojej pracy jako silne oczekiwanie decydentów, jeśli chodzi o cykliczne raportowanie. Jest to bardzo prosty wskaźnik pokazujący przeciętną wartość klientów. Stałe monitorowanie ARPU daje możliwość sprawdzania, na ile założone plany przychodowe w połączeniu ze strukturą klientów są realizowane.
ARPU nie pokaże nam szczegółów zmian zachodzących w portfelach usług naszych klientów, nie jest segmentacją, nie wyjaśnia przyczyn zmian. Jest natomiast niewątpliwie wdzięcznym KPI do pokazywania w raportach zarządczych – szczególnie jeśli rośnie.
Czas uruchomić KNIME
Interfejs był już omawiany w poprzednich artykułach, więc pozwolę sobie od razu przejść do budowy strumienia1.
Przechodzimy zatem do Menu/File/New i w oknie dialogowym wybieramy New Knime Workflow.
W następnym kroku możemy nasz nowy workflow nazwać arpu i zapisać go w domyślnej lokalizacji2. Nasz nowy workflow zobaczymy w oknie Knime Explorer w lewym górnym rogu interfejsu. Dwukrotne kliknięcie na plik otworzy nam pustą przestrzeń głównego okna budowania strumienia.
Import danych
Nie ma analizy bez danych, więc musimy zacząć od ich zaczytania. KNIME pozwala na pracę z danymi z bardzo różnorodnych źródeł. Możemy oczywiście otwierać pliki płaskie, takie jak xlsx, csv, txt, pdf. Możemy łączyć się z relacyjnymi bazami danych
i nawet zlecać im wykonywanie operacji. Paleta źródeł danych jest jednak dużo szersza i cały czas rozwijana. Dzisiaj wykorzystamy klasykę klasyki, czyli CSV READER.
Na rysunku numer 4 – okna Knime Explorer jest okno Node Repository, gdzie zgromadzone są wszystkie tzw. węzły (nodes), których używamy do budowy strumienia.
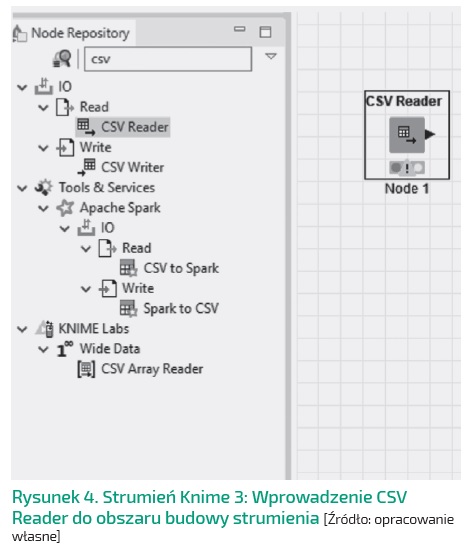
Są one pogrupowane, czyli np. węzły dostępu do plików płaskich znajdziemy w katalogu IO. Dla potrzeb artykułu będziemy jednak korzystać z dostępnej w oknie przeglądarki. Dzięki niej, znając nazwę danego węzła lub jej część, szybko go zlokalizujemy. Wpisujemy zatem csv.
Przeglądarka znalazła wszystkie węzły mające w nazwie csv. Wybieramy CSV Reader i klikamy go dwukrotnie. W efekcie pojawi się na środku pustego workflow. Łapiąc węzeł lewym przyciskiem myszy i zatrzymując się na obramowaniu, możemy węzeł umieścić w dowolnym miejscu pustego obszaru roboczego. Słuszną koncepcją będzie tu umieszczenie węzła źródła danych blisko lewej krawędzi.
Warto tu na marginesie zwrócić uwagę na różnice w stosunku do Excela. W KNIME, jak i innych narzędziach Data Mining, co do zasady nie ingeruje się w źródło danych. Dane możemy w dowolny sposób przekształcać, ale nie wykonujemy na nich operacji znanych z Excela.
Następnie klikamy dwukrotnie na umieszczony w obszarze roboczym węzeł i wprowadzamy ustawienia importu danych
(Rysunek 5)
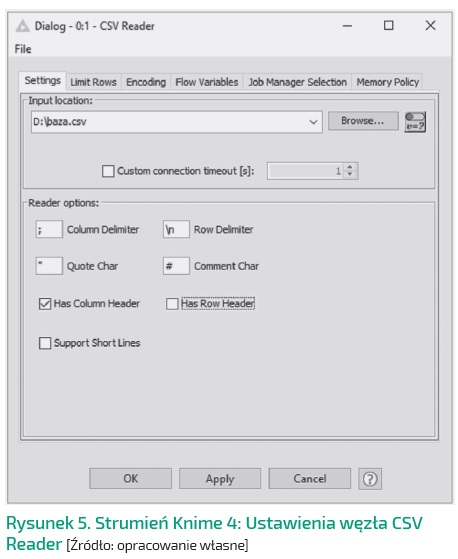
W oknie dialogowym należy przede wszystkim wprowadzić ścieżkę lokalizacji pliku. Nasza baza jest separowana średnikiem, więc trzeba w oknie Column Delimiter zmienić domyślny przecinek na średnik. Warto również odznaczyć check box Has Row
Header, gdyż w danych nie ma identyfikatora wierszy. Klikamy OK.
W podstawowych ikonach pod Menu znajdziemy zielony przycisk startu, który należy teraz uruchomić, aby wprowadzić dane do analizy.
W efekcie nasz węzeł wykonał się i czerwona dotąd kropka pod ikoną zmieniła się na zieloną (Rysunek 6).

Wykorzystałeś swój limit bezpłatnych treści
Pozostałe 57% artykułu dostępne jest dla zalogowanych użytkowników portalu. Zaloguj się, wybierz plan abonamentowy albo kup dostęp do artykułu/dokumentu.
 Zaloguj się
Zaloguj się











