Praktyka czyni mistrzów, czyli tworzymy workflow w KNIME (cz. 1)
Moja przygoda z KNIME miała dwa początki. Za pierwszym razem dowiedziałem się, że taki program istnieje, zainstalowałem go i tyle. Nie wiedziałem, jak łączyć ze sobą te kwadraty, aby z sensem przetwarzać dane. Drugi początek był wtedy, gdy zobaczyłem, jak ktoś praktycznie używa KNIME, i przekonałem się, że to nie jest tak skomplikowane. A przede wszystkim – rozbudziłem w sobie ciekawość. Dziś zadbam, aby ten cykl artykułów nie wymagał drugiego początku w jakimś innym miejscu i czasie.







W poprzednich częściach naszego cyklu przedstawiałem szczegóły dotyczące wyglądu i używania KNIME. Pokazałem, jak prosty w obsłudze i jednocześnie bogaty w funkcje jest to program. Jednak nadal wśród wielu czytelników może być żywa wątpliwość – czy faktycznie jest to program dla mnie? Co i – przede wszystkim – jak można w nim zrobić? Rozumiem, że proste przedstawienie historii tej rewelacyjnej aplikacji i jej interfejsu może być niewystarczające, aby przełamać opór przed stworzeniem swojego własnego workflow. Pamiętam, jak na początku było mi trudno zrozumieć zalety KNIME, dopóki nie zobaczyłem, jak robi się prosty schemat przepływu danych.
Dlatego dziś zrobimy to razem.
Wiekowanie rozrachunków oparte na zestawieniu faktur
Postanowiłem wziąć na warsztat coś prostego, a jednocześnie pokazującego kilka trochę bardziej zaawansowanych funkcji KNIME. Stąd pomysł na stworzenie wiekowania rozrachunków opartego na zestawieniu faktur. Mam świadomość, że tego typu raporty można tworzyć za pomocą innych narzędzi lub prościej w KNIME, niż w pokazany przeze mnie sposób. Mam jednak nadzieję, że ten prosty workflow zainspiruje do poszukiwań i tworzenia własnych narzędzi.
Zanim zaczniemy, przypomnę, że wszystkie węzły wyszukuje się w oknie Node Repository – a następnie przeciąga do obszaru roboczego lub przenosi je tam podwójnym kliknięciem. Jeśli w obszarze roboczym mamy już zaznaczony jakiś węzeł, podwójne kliknięcie spowoduje automatyczne połączenie już istniejącego węzła z właśnie dodawanym. Warto weryfikować te połączenia i w razie niespójności korygować je, przeciągając ręcznie łącza z portu wyjścia do portów wejścia. Właściwości każdego z węzłów edytujemy poprzez dwukrotne kliknięcie na nim, gdy znajduje się w obszarze roboczym, a zatwierdzamy je, klikając OK. Dobrą praktyką jest też testowanie workflow poprzez uruchamianie go po dodaniu kolejnego węzła (można użyć przycisku F7 na zaznaczonym węźle) i sprawdzaniu otrzymanych danych poprzez kliknięcie prawym przyciskiem myszy na porcie wyjścia i wybranie ostatniej opcji z menu.
Na potrzeby tego przykładu oprę się na fikcyjnych danych, ale jestem przekonany, że każdy z czytelników będzie w stanie łatwo dostosować tego typu workflow do działania na raportach, jakie uzyskuje ze swojego systemu finansowo-księgowego. Przyjmuję też, że dany raport otrzymujemy w formie pliku Excela (.xlsx lub .csv). Nie ma jednak przeciwwskazań, aby nie skorzystać z węzła pozwalającego na pobranie tych danych bezpośrednio z bazy danych systemu za pomocą zapytania SQL. Wiem, że nie każda firma ma taką możliwość – a niejednokrotnie także chęć na bezpośrednią ingerencję w dane programu. Z kronikarskiego obowiązku zaznaczam więc, że jest to możliwe i wymaga tylko kilku dodatkowych węzłów obsługujących zapytania SQL.
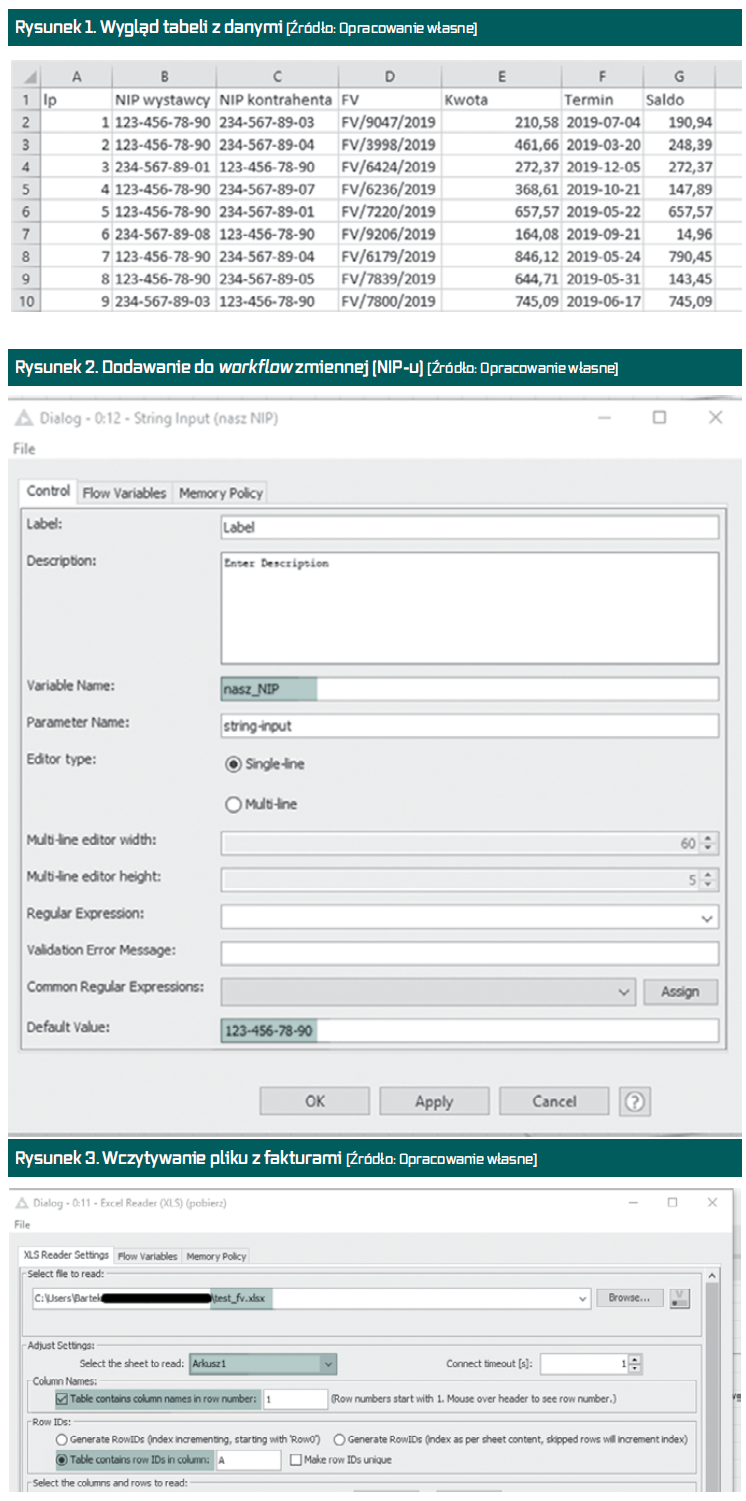
Przyjmijmy zatem, że z naszego systemu uzyskaliśmy plik, w którym są następujące kolumny (Rysunek 1):
- liczba porządkowa (lp.),
- NIP wystawcy faktury (NIP wystawcy),
- NIP odbiorcy faktury (NIP kontrahenta),
- numer faktury (FV),
- kwota brutto faktury (Kwota),
- termin płatności faktury (Termin),
- saldo faktury na dany dzień (Saldo).
Wykorzystałeś swój limit bezpłatnych treści
Pozostałe 70% artykułu dostępne jest dla zalogowanych użytkowników portalu. Zaloguj się, wybierz plan abonamentowy albo kup dostęp do artykułu/dokumentu.
 Zaloguj się
Zaloguj się











