Prognozowanie z wykorzystaniem uczenia maszyn
Któż z nas nie chciałby trafnie przewidywać przyszłości? Potrzeba przewidywania występuje nieomal wszędzie: w życiu codziennym, gdy np. chcemy zaplanować najlepszy termin wakacji, potrzebujemy trafnej prognozy pogody; w zarządzaniu, gdy potrzebujemy przewidzieć popyt; w produkcji, gdzie np. możemy przewidywać uzyski poszczególnych produktów. Istnieje wiele różnych sposobów przewidywania, a w tym artykule zajmiemy się prognozowaniem na podstawie danych o przebiegu zjawiska w przeszłości.







Prognoza stworzona na potrzeby tego artykułu, będzie wyznaczana przez model stworzony za pomocą sieci neuronowych, jednej z najpopularniejszych metod uczenia maszyn (ang. machine learning). Zagadnienie omówimy na praktycznym przykładzie. Pokażemy – oczywiście w pewnym skrócie – wszystkie kroki projektu analitycznego: analizę biznesową, eksplorację i przygotowanie danych, stworzenie modelu prognostycznego i jego ocenę.
Analiza biznesowa
Pierwszym krokiem każdego projektu analitycznego jest analiza biznesowa, w szczególności dokładne zdefiniowanie celu projektu, przełożenie tego celu na język danych, ustalenie dostępnych danych, określenie ograniczeń i wymagań dotyczących projektu. Chodzi o to, aby uniknąć sytuacji, gdy wynikiem projektu jest bardzo trafny model, który jednocześnie jest bezużyteczny.
Dla przykładu rozważmy przewidywanie liczby kontaktów z biurem obsługi klienta na potrzeby optymalizacji zasobów. Najmniejszy błąd prognozy może mieć model wykorzystujący do wyznaczania przewidywań liczbę kontaktów z poprzedniego dnia. Jednak taki model jest bezużyteczny, gdy zmiana liczby pracowników zaplanowanych na konkretny dzień jest możliwa z wyprzedzeniem co najmniej dwóch dni: potrzebną prognozę dostaniemy za późno, aby podjąć działania.
W naszym przypadku zadanie polegało na codziennym przewidywaniu na następne siedem dni liczby klientów placówki handlowej w poszczególnych godzinach. Podczas analizy biznesowej ustalono, że maksymalny dopuszczalny, średni bezwzględny błąd procentowy prognozy dla nowych danych ma wynieść 7%.
Do dyspozycji mamy dane z przeszłości o liczbie klientów placówki handlowej w ciągu godziny za okres od początku stycznia do końca sierpnia. Ponadto mamy dane „kalendarzowe”: dzień tygodnia, czy danego dnia było święto i godzinę. Placówka pracowała w godzinach od 6 do 22, siedem dni w tygodniu, była również otwarta w święta. Nasze dane to dane rzeczywiste przeskalowane i zaszumione dla zachowania poufności.
Wybór metody prognozowania
Głównym celem projektu jest uzyskanie jak najtrafniejszych przewidywań i dlatego użyjemy sieci neuronowych, które nie są łatwo interpretowalne dla człowieka, ale za to dają trafne przewidywania. Sieci neuronowe są jedną z najczęściej używanych metod uczenia maszyn. Inspiracją dla sieci neuronowych jest działanie układu nerwowego. Sztuczną sieć neuronową tworzą połączone ze sobą jednostki – sztuczne neurony. Na Rysunku 1 widzimy schemat prostej sieci.

Jeśli naszym zadaniem jest przewidywanie wartości zmiennej zależnej (wyjścia) na podstawie zmiennych niezależnych (wejść), to najczęściej stosujemy sieci złożone z warstw, a sygnał przechodzi z jednej warstwy do drugiej: są to tzw. sieci jednokierunkowe. Zazwyczaj sieć ma warstwę wejściową, jedną lub wiele warstw ukrytych oraz warstwę wyjściową.
Jednostki warstwy wejściowej wstępnie przetwarzają zmienne niezależne modelu (najczęściej skalują je do przedziału [0,1]) i podają wstępnie przetworzone wartości na wejścia jednostek warstwy ukrytej.
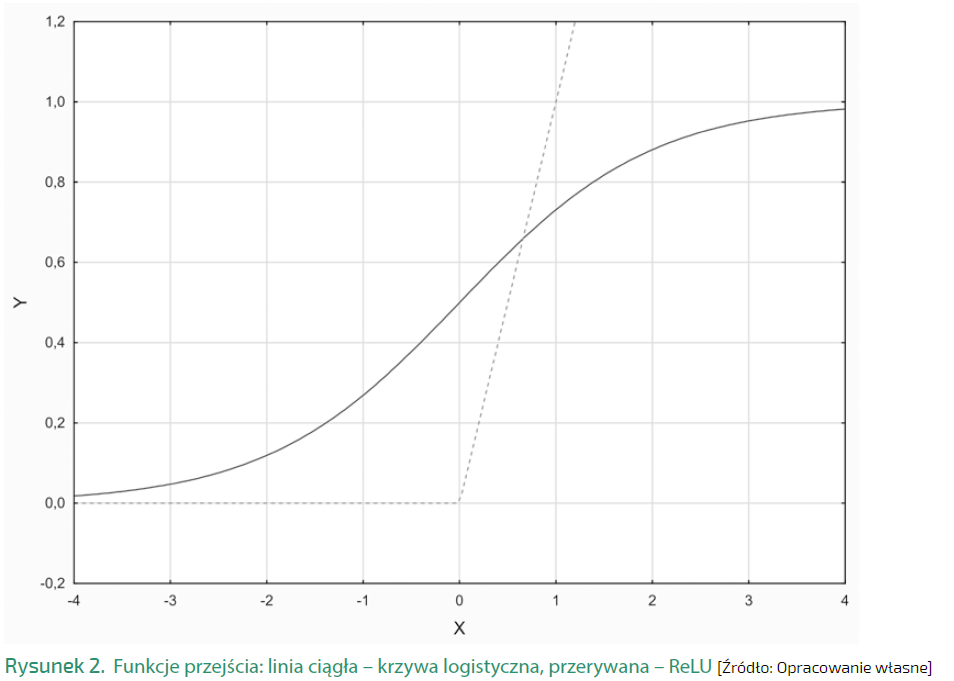
Każda z jednostek warstwy ukrytej i wyjściowej ma wiele wejść i jedno wyjście. Na wejściach neuronu podajemy wyjścia innych neuronów. Każdemu wejściu przypisana jest waga. Uczenie sieci neuronowej polega właśnie na znalezieniu najlepszych wag. W celu wyznaczenia wartości na wyjściu neuronu najpierw wykonywana jest agregacja wartości na wejściu. Najczęściej mnożymy wartości na wejściu przez wagi i sumujemy. Do tak uzyskanej liczby dodajemy jeszcze stałą (wyraz wolny lub przesunięcie). Wyjście neuronu obliczane jest jako wartość tzw. funkcji przejścia (lub aktywacji), której argumentem jest wynik agregacji. Tradycyjnie jako funkcję przejścia stosuje się funkcję przypominającą rozciągniętą literę S, np. funkcję logistyczną postaci f(x)= 1/(1+exp{-x}). W głębokim uczeniu (ang. deep learning) używana jest funkcja ReLU: jest ona równa 0 dla ujemnych wartości x, a dla dodatnich x jest równa x. Funkcje aktywacji przedstawione są na Rysunku 2.
Kluczową zaletą sieci neuronowych jest możliwość odtworzenia dowolnej zależności między zmiennymi niezależnymi a zależnymi. Wadą sieci jest to, że ich model jest trudny w interpretacji, nie dostajemy jawnego wzoru lub reguły, tak jak to jest w przypadku regresji liniowej i drzew decyzyjnych. Ponadto sieci wymagają danych dobrej jakości: występowanie obserwacji odstających, pustych zmiennych, braków danych utrudnia znalezienie dobrego modelu.
Opracowano wiele sposobów uczenia sieci, funkcji przejścia, dodatkowych przekształceń oraz technik umożliwiających uzyskanie optymalnych sieci. Z praktycznego punktu widzenia nie musimy się nimi zajmować, gdyż zastosujemy narzędzie, które sprawdza automatycznie wiele ustawień i wybiera najlepsze.
Narzędzie analityczne
Model prognostyczny stworzymy w programie Statistica (statistica.pl). Modele uczenia maszynowego w Statistice tworzymy w środowisku graficznym, bez konieczności pisania żadnego kodu (aczkolwiek można korzystać ze skryptów Python i R).
Podstawowym środowiskiem Statistiki jest przestrzeń robocza. Jest to coś w rodzaju tablicy, na której rysujemy schemat operacji wykonywanych przez program. Schemat taki obejmuje wszystkie kroki wydobywania z danych użytecznej wiedzy: od pobrania danych, przez ich sprawdzenie, oczyszczenie, przekształcenie, właściwą analizę, aż do zastosowania jej wyników dla nowych danych, zapisania wyników w zewnętrznej bazie danych itp. W przestrzeni roboczej źródła danych procedury analityczne i wyniki reprezentowane są przez ikony (tzw. węzły), a przepływ danych obrazują strzałki łączące węzły (zob. Rysunek 3). Najważniejsze zalety przestrzeni roboczych to:
- łatwa orientacja w złożonych projektach analitycznych,
- uruchomienie wieloetapowych analiz jednym poleceniem,
- modyfikowanie scenariuszy analiz przy minimalnym nakładzie pracy,
- wszystkie etapy analiz, pośrednie wyniki i dokumenty ujęte są w jednym dokumencie,
- automatyczna dokumentacja projektów.
Wykorzystałeś swój limit bezpłatnych treści
Pozostałe 47% artykułu dostępne jest dla zalogowanych użytkowników portalu. Zaloguj się, wybierz plan abonamentowy albo kup dostęp do artykułu/dokumentu.
 Zaloguj się
Zaloguj się











