Knime Analytics Platform - analiza przeciętnych wynagrodzeń i emerytur Polaków w ostatnich 15 latach
W poprzednim numerze „Informacji Zarządczej” pozyskaliśmy ciekawe dane i stworzyliśmy pierwszy workflow w KNIME. Jeden z systemów GUS – Bank Danych Lokalnych – posłużył jako źródło danych o wynagrodzeniach i emeryturach Polaków w ostatnich 15 latach. Eksportowane dane w plikach csv dodaliśmy do workflow na zasadzie „przeciągnij i upuść”.







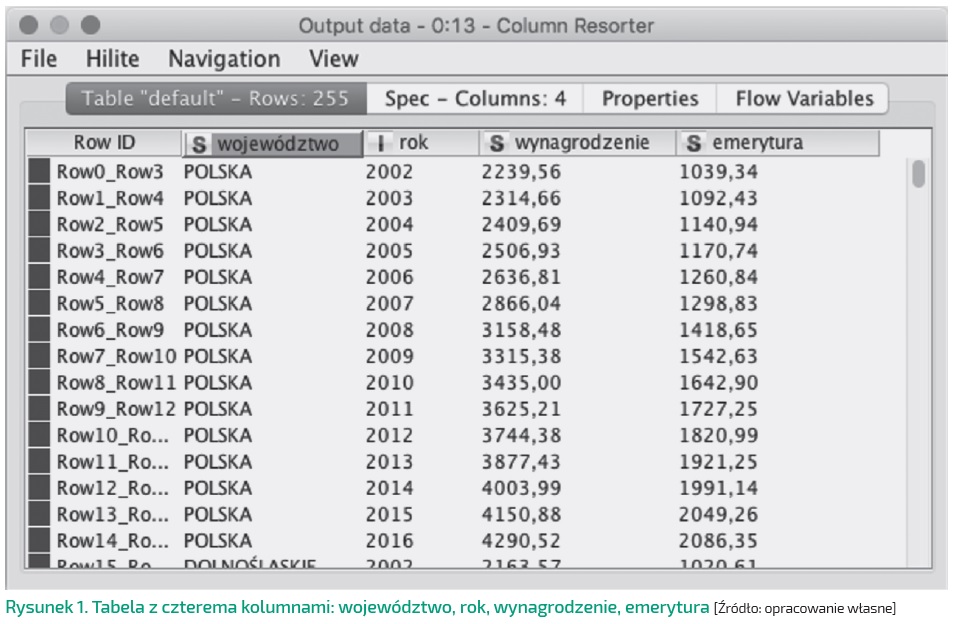
Następnie, łącząc dane i wykonując kilka przekształceń przy użyciu węzłów z kategorii manipulowania danymi (Node Repository – Manipulation) uzyskaliśmy efekt w formie tabeli z czterema kolumnami: województwo, rok, wynagrodzenie, emerytura (Rysunek 1). Tym razem zajmiemy się agregacją danych. W tym celu wykorzystamy jeden z bardziej zaawansowanych węzłów do wyliczania miar statystycznych – GroupBy.
Kontrola typu zmiennych
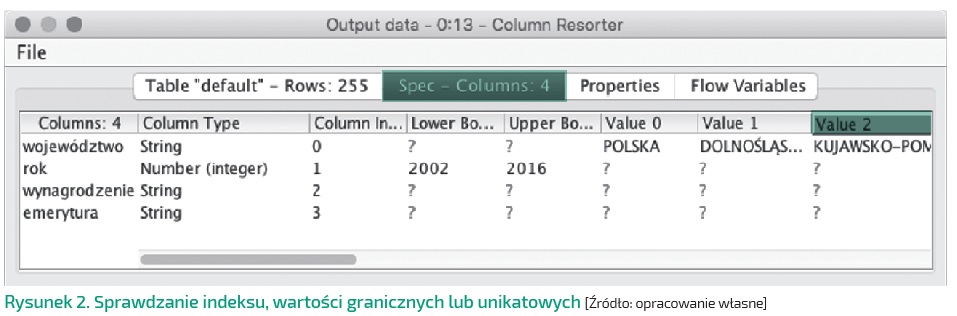
Zanim przejdziemy do agregacji, warto jeszcze skontrolować typ zmiennych w poszczególnych kolumnach. Nagłówki kolumn widoczne w podglądzie danych zawierają pierwsze litery od nazw typów, np. „S” jak String czy „I” jak Integer. Z kolei w zakładce ze specyfikacją kolumn oprócz pełnych nazw typów możemy również sprawdzić indeks, wartości graniczne lub unikatowe (Rysunek 2).
Konwersja typu zmiennych
Wyraźnie widać, że w przypadku analizowanych danych powinniśmy zmienić typ kolumn „wynagrodzenie” i „emerytura”. Z typu tekstowego String na liczbowy Double. Inaczej wyliczanie jakichkolwiek miar statystycznych nie będzie możliwe.
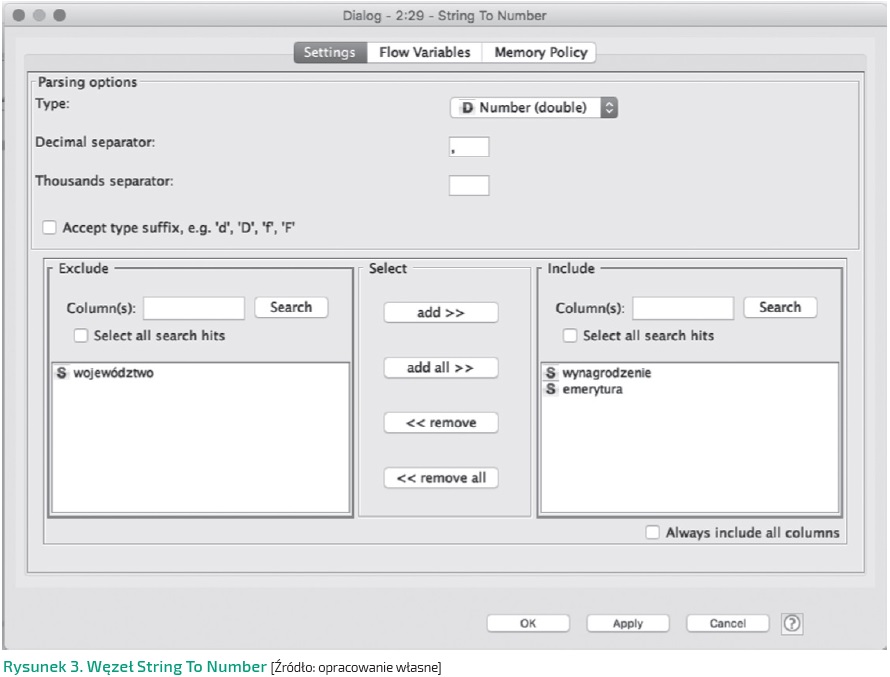
Korzystając z węzła String To Number, możemy w prosty sposób skonwertować typ zmiennych.
Wystarczy wybrać docelowy typ, separator oraz dodać wybrane kolumny do sekcji Include (Rysunek 3).
Agregacja danych
Po konwersji typów możemy przejść do agregacji danych. Węzeł GroupBy wyszukujemy w repozytorium lub w widoku Workflow Coach. Dołączając na koniec, uzyskujemy całościowo workflow jak na Rysunku 4.
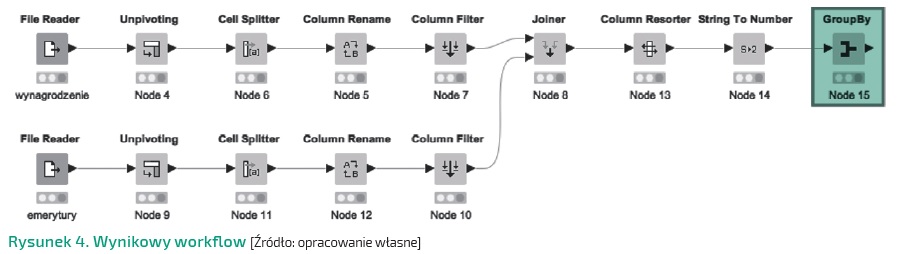
Warto zauważyć, że GUI KNIME umożliwia wizualne porządkowanie przestrzeni workflow za pomocą kilku użytecznych funkcji, takich jak adnotacje, meta nodes (Rysunek 5) czy skalowanie obszaru roboczego – możliwości te zostaną jeszcze zaprezentowane w ramach cyklu.
Węzeł GroupBy umożliwia grupowanie danych oraz agregowanie wartości według różnych metod statystycznych (i nie tylko) opisanych w zakładce Description (Rysunek 6).

Wykorzystałeś swój limit bezpłatnych treści
Pozostałe 65% artykułu dostępne jest dla zalogowanych użytkowników portalu. Zaloguj się, wybierz plan abonamentowy albo kup dostęp do artykułu/dokumentu.
 Zaloguj się
Zaloguj się











